Module 1.2 Les principes de base en modélisation
Résumé du module
Dans ce module, nous étudions les principes de base en modélisation. Ce module inclut deux activités : une activité de lecture et une activité d’auto-évaluation.
Dans un premier temps, nous présentons une catégorisation générale des modèles selon quatre types : les modèles physiques, les modèles conceptuels, les modèles mathématiques et les modèles récursifs. Nous définissons ensuite d’autres propriétés qui permettent de distinguer les modèles : statique ou dynamique, déterministe ou stochastique et continu ou discret.
Dans un deuxième temps, nous discutons de l’élaboration d’un modèle conceptuel. Quels en sont les éléments importants? Quelles réflexions le modélisateur doit-il privilégier? Quelle terminologie utilisée?
Dans un troisième temps, nous expliquons les étapes du processus de modélisation, depuis la conception du modèle conceptuel jusqu’à l’analyse des résultats produits par le modèle final. L’activité 1 est consacrée à la lecture d’un article du comité technique de la Society for Computer Simulation qui présente les étapes de ce processus et décrit la terminologie utilisée.
Nous complétons ce module par une activité d’autoévaluation. Cette activité a pour objectif d’évaluer votre compréhension du contenu des modules 1.1 et 1.2 sur le rôle des modèles en science de l’environnement et des principes de base en modélisation.
Introduction
Nous avons vu au module 1.1 que les modèles servent à représenter la structure, le fonctionnement ou la dynamique d’un système. Différents types de modèles peuvent accomplir ces fonctions. Le modélisateur ou la modélisatrice doit choisir le type de modèle qui sied le mieux à l’objectif de son étude.
Les types de modèles
Nous pouvons diviser les modèles en quatre catégories générales : les modèles physiques, les modèles conceptuels, les modèles mathématiques et les modèles récursifs.
Les modèles physiques
Les modèles physiques sont des modèles réduits du système étudié. Ils présentent une géométrie et une dynamique fortement similaires au système réel, mais à une échelle spatiale ou temporelle plus petite. Il existe une grande variété de modèles physiques. La maquette d’une construction ou d’un aménagement urbain est un exemple de modèle physique (figure 1.2.1a). Une soufflerie est un modèle physique utilisé en aérodynamique pour étudier les effets de l’écoulement de l’air sur des véhicules aériens (figure 1.2.1b).

Figure 1.2.1 Exemples de modèle physique : a) Maquette de la ville de Shanghai (Jordiferrer, 2007) et b) Soufflerie (JeLuF, 2003).
Biosphere 2 est un modèle physique plus complexe (figure 1.2.2). Cette installation d’envergure couvre 1,28 hectare et reproduit, dans un environnement entièrement clos, plusieurs biomes de la terre (désert, savane, forêt humide, etc.). Cet écosystème artificiel est utilisé comme laboratoire géant pour conduire diverses expériences en sciences environnementales.

Figure 1.2.2 Le modèle physique Biosphere 2 (Johndedios, 2011).
Les modèles conceptuels
Les modèles conceptuels constituent une représentation schématique du système étudié qui illustre les composantes et les processus principaux du système selon un objectif ou une question de recherche. Par exemple, la figure 1.2.3 montre un modèle conceptuel de changements d’occupation du sol sur un territoire. On y voit les composantes importantes (la population, les emplois, le territoire, les écosystèmes naturels) et les processus (la croissance de la population, la mobilité de la population, la fragmentation, la pollution, etc.) qui influencent les changements possibles entre les utilisations du sol, par exemple un site naturel qui devient résidentiel.

Figure 1.2.3 Modèle conceptuel de changement d’utilisation du sol (adapté de Engelen et al., 1995).
La figure 1.2.4 illustre un modèle conceptuel de l’érosion du sol où sont représentées les interactions entre les principaux facteurs responsables du détachement et du transport des particules du sol (les précipitations, l’érodabilité du sol, la rugosité du sol, la pente, la capacité de stockage en surface, etc.).
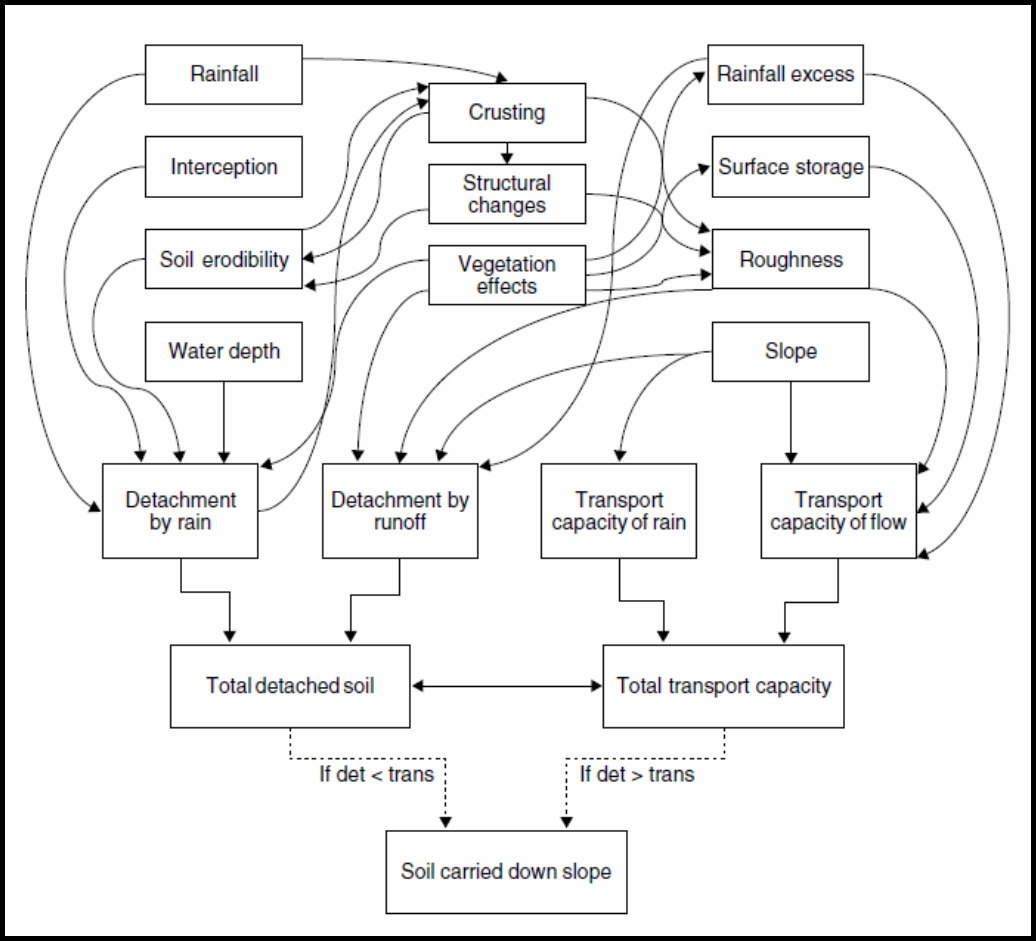
Figure 1.2.4 Modèle conceptuel des interactions entre les facteurs qui contribuent à l’érosion du sol (Quinton, 2004).
Les modèles mathématiques
Les modèles mathématiques représentent une relation entre deux ou plusieurs variables par une ou des équations mathématiques. Les modèles mathématiques peuvent être empiriques ou théoriques. Un modèle mathématique empirique correspond à la fonction mathématique ou à une distribution statistique qui représente le mieux la relation entre une série d’observations empiriques. Un modèle mathématique empirique est le résultat d’un compromis entre exactitude et simplicité : la fonction mathématique doit être précise dans sa représentation des données tout en étant le plus simple possible. La précision ou la validité de la fonction est évaluée par des tests statistiques. Les modèles mathématiques empiriques sont souvent spécifiques aux données étudiées et sont donc difficilement généralisables à d’autres situations.
La figure 1.2.5 est un exemple d’un modèle mathématique de la croissance de peuplement d’arbres à bois dur. Ce modèle quantifie la relation entre le volume moyen de bois, VS, et l’âge d’un peuplement, A, à partir de données d’inventaire forestier de l’écozone des plaines boréales en Saskatchewan (Stinson et al., 2011). L’adéquation du modèle avec les données échantillonnées est mesurée par le coefficient de détermination R2.
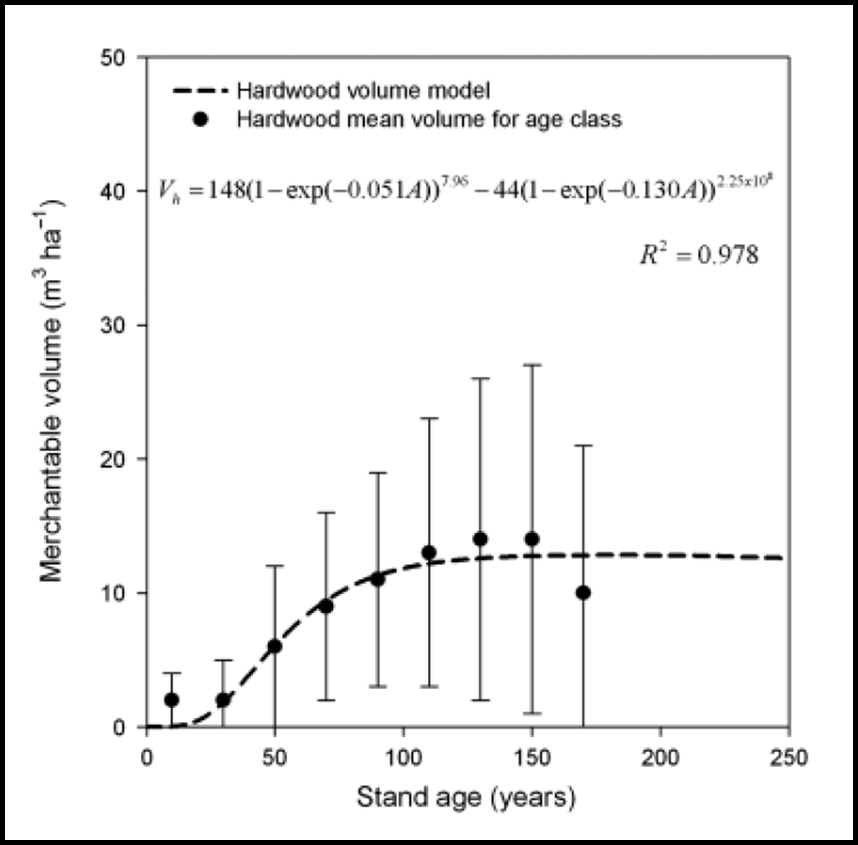
Figure 1.2.5 Un modèle mathématique empirique du volume de bois en fonction de l’âge du peuplement forestier (figure adaptée de Stinson et al., 2011).
La figure 1.2.6 illustre la distribution empirique de l’abondance de 159 espèces de vertébrés échantillonnées dans la forêt pluviale Australian Wet Tropics (Williams et al., 2009). Cette distribution est exprimée par un histogramme qui répartit le nombre d’espèces observées selon leur abondance. La barre de gauche contient les espèces les moins abondantes (100 à 300 individus) et celle de droite les espèces les plus abondantes (entre 107 et 107,5 individus). La courbe noire est la distribution gaussienne qui démontre la meilleure concordance avec ces observations.
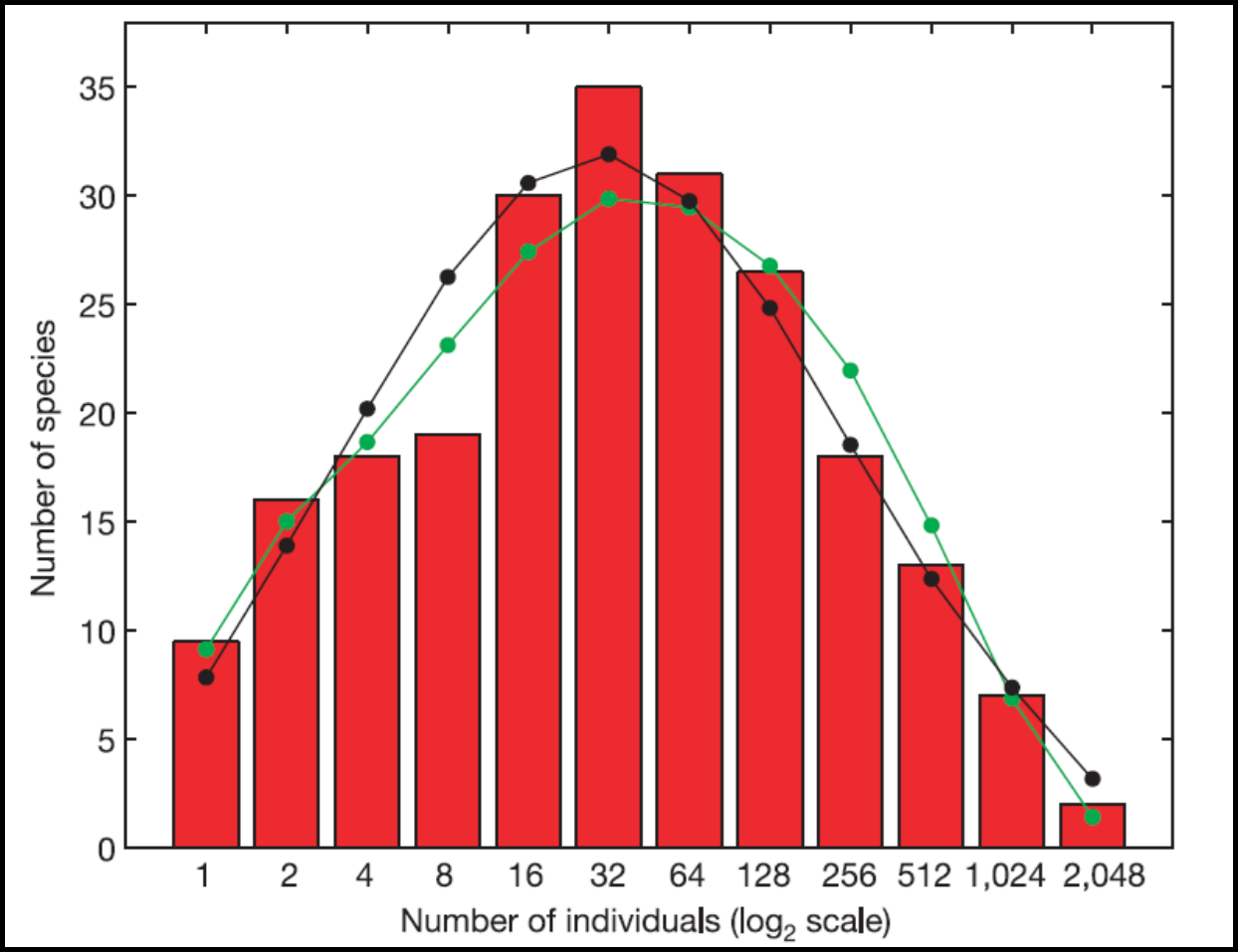
Figure 1.2.6 Distribution de l’abondance de 159 espèces de vertébrés dans la forêt pluviale Australian Wet Tropics. Le modèle mathématique (courbe noire) est une distribution gaussienne correspondant avec justesse à l’histogramme empirique (figure de Williams et al., 2009).
Dans les modèles mathématiques théoriques, ce sont les processus propres au système d’étude qui sont modélisés par des fonctions mathématiques. Ces fonctions sont formulées à partir d’hypothèses concernant la nature des relations entre les variables d’un système ou sur des principes ou des lois (physique, chimique, économique ou autre). Les modèles mathématiques théoriques sont alors testés sur des données empiriques. La correspondance entre le modèle formulé et les données indique que les hypothèses à la base du modèle expliquent probablement le comportement du système. Par contre, une absence de correspondance montre que les hypothèses ne permettent pas d’expliquer le comportement du système. D’autres hypothèses quant aux processus qui gouvernent le système doivent alors être formulées. Les modèles mathématiques théoriques peuvent habituellement être utilisés dans différentes situations. Ils sont ainsi plus généralistes que les modèles empiriques.
Le modèle de croissance logistique est un exemple de modèle mathématique théorique fréquemment utilisé en écologie des populations (nous en reparlerons au module 2.2). Ce modèle exprime par une fonction mathématique l’hypothèse spécifiant que la croissance d’une population est limitée par la quantité de ressources disponibles dont elle dépend :

Dans cette équation, N(t) est la taille de la population au temps t, et N0 est la taille de la population au temps initial t = 0. r est le taux de croissance intrinsèque de la population – c’est-à-dire le taux avec lequel la population augmenterait si les ressources étaient illimitées. K est la quantité maximale de ressources disponibles. On appelle K la capacité de soutien du système. Lorsque la population atteint la taille K ( N(t) = K ), elle cesse de croître. Le modèle logistique prédit donc que la taille de la population plafonne autour de la valeur maximale K.
La figure 1.2.7 illustre la croissance de la population de quatre espèces de protozoaires cultivées en laboratoire (Vandermeer, 1969) : Paramecium bursaria, Blepharisma sp, Paramecium caudatum et Paramecium aurelia. Chacune de ces courbes de croissance peut être expliquée relativement bien par le modèle logistique (courbe noire) pour différentes valeurs des paramètres r et K.
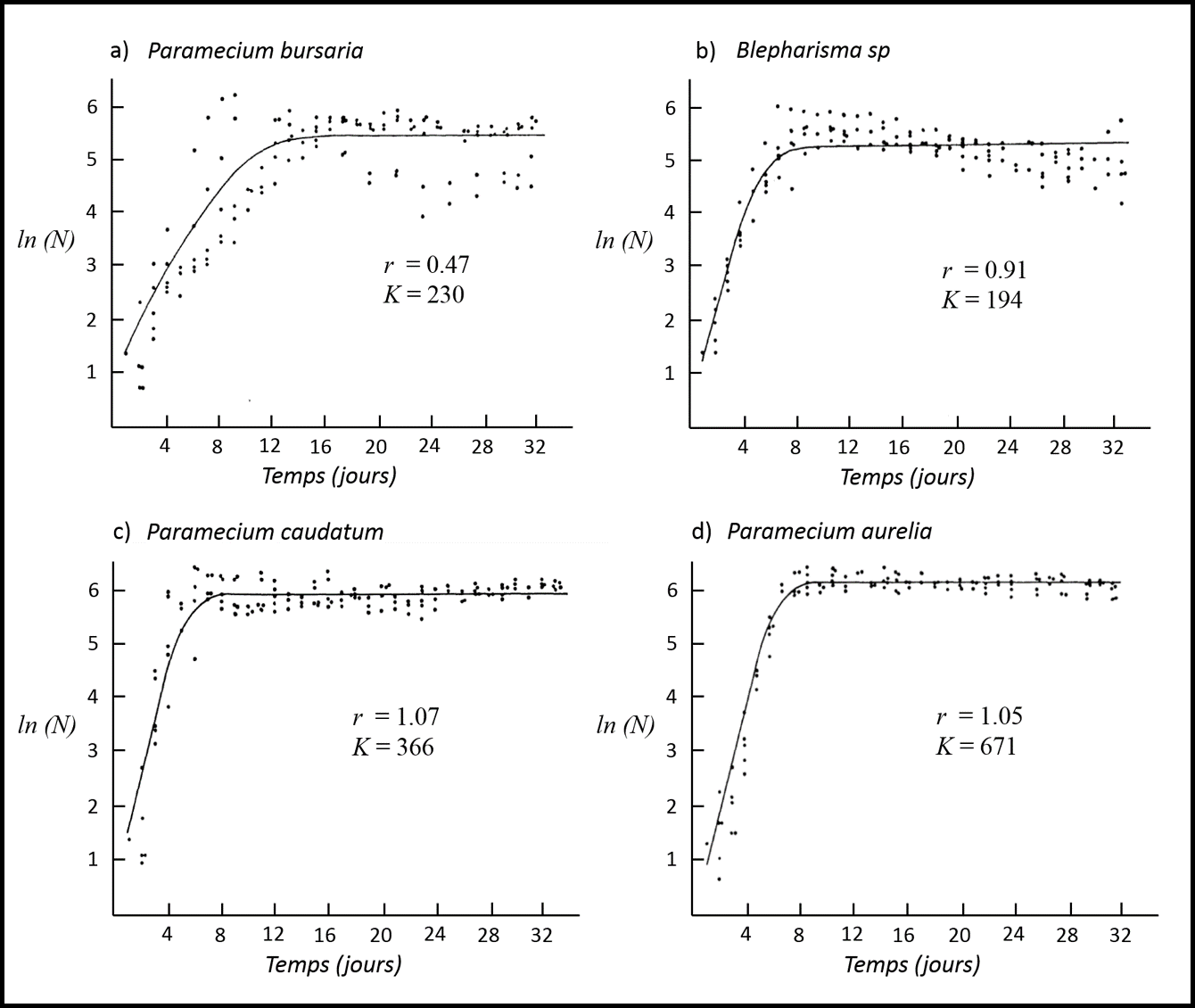
Figure 1.2.7 Applications du modèle mathématique théorique de croissance logistique sur quatre espèces de protozoaires cultivées en laboratoire : a) Paramecium bursaria, b) Blepharisma sp, c) Paramecium caudatum et d) Paramecium aurelia. Figure adaptée de Vandermeer (1969) et de Roughgarden (1979).
Les modèles récursifs
Les modèles récursifs représentent les processus propres au système d’étude par des règles de transition qui agissent sur les composantes du système pour en changer leur état. Dans un modèle récursif, le temps est une variable discrète (nous expliquerons cette distinction plus bas) appelée souvent une itération. Une règle de transition décrit l’état du système à l’itération future en fonction de son état à l’itération présente (figure 1.2.8) :
 .
.
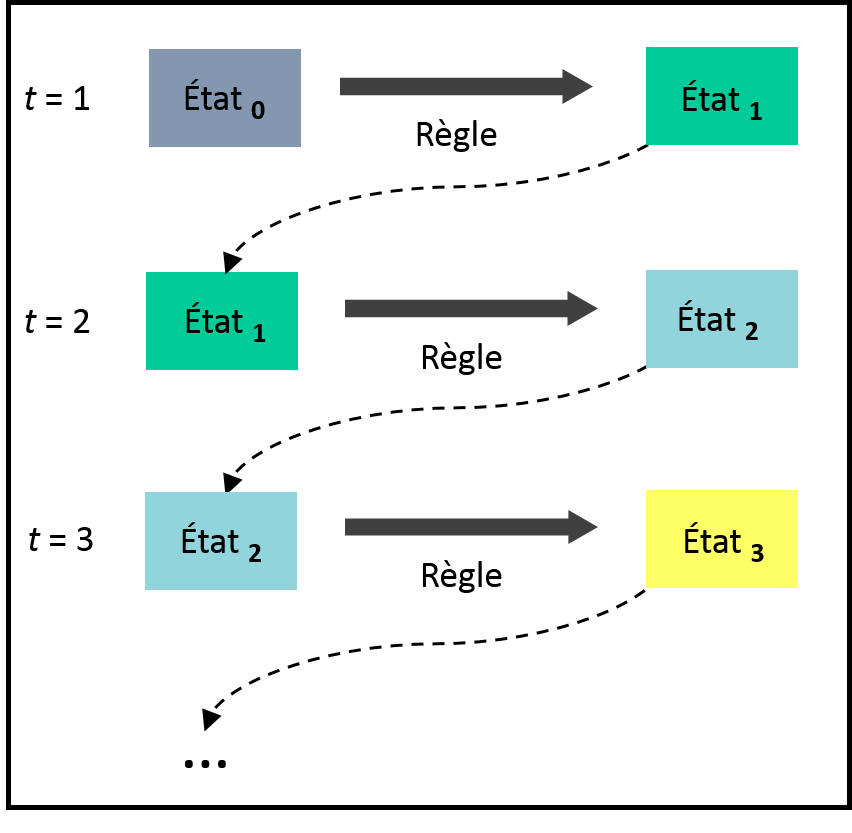
Figure 1.2.8 Représentation conceptuelle d’un modèle récursif. À chaque itération du modèle, l’état du système est actualisé selon une règle de transition.
Par exemple, un modèle de propagation d’une maladie infectieuse au sein d’une population pourrait contenir la règle de transition suivante : si un individu sain à l’itération t entre en contact avec un individu infecté, il devient lui aussi infecté à l’itération t + 1.
Une règle de transition peut aussi s’exprimer par une fonction mathématique. Par exemple, il existe aussi un modèle récursif pour représenter la croissance logistique (équation 1).

Contrairement à un modèle mathématique théorique, l’état futur du système n’est pas prédit en résolvant une équation mathématique. Le modèle doit être simulé, c’est-à-dire que l’état du système à chaque itération t doit être calculé.
Considérons par exemple le modèle logistique récursif (équation 2) en utilisant les paramètres r = 0,8 et K = 10. Si à l’itération initiale t = 0 la taille de la population est N(0) = 2, la simulation du modèle produira les valeurs successives suivantes :
(3)

Et ainsi de suite pour les itérations subséquentes.
Il existe différentes approches de modélisation récursive. Les équations de différences, les automates cellulaires, les modèles orientés-individus et les modèles multi-agents en sont des exemples. Nous présenterons ces approches dans les modules 2.2, 2.3 et 2.4.
Autres distinctions
Les modèles peuvent être caractérisés sur la base de propriétés additionnelles (Aral, 2010).
Statique ou dynamique
Un modèle peut être statique ou dynamique. Un modèle statique représente la structure ou le fonctionnement d’un système à un moment fixe dans le temps. Une maquette ou le schéma organisationnel d’une entreprise sont des modèles statiques. Le modèle mathématique empirique qui représente la distribution de l’abondance des espèces (figure 1.2.6) est aussi un modèle statique. Ce modèle ne tient pas compte de la fluctuation possible dans l’abondance des espèces au cours du temps.
Un modèle dynamique inclut la dimension temporelle. La simulation d’un modèle dynamique détermine l’état futur du système pour des valeurs croissantes du temps. Ainsi, un modèle dynamique permet de reproduire l’évolution temporelle du fonctionnement et du comportement d’un système en fonction des paramètres assignés. Un modèle dynamique est aussi appelé un modèle de simulations. Les modèles dynamiques peuvent être des modèles mathématiques. Par exemple, le modèle de croissance logistique définit la taille de la population N en fonction du temps t (équation 1). Les modèles récursifs sont aussi des modèles dynamiques où les itérations sont répétées pour connaître l’état futur du système.
Déterministe ou stochastique
Un modèle peut être déterministe ou stochastique. On dit qu’un modèle est déterministe lorsque les « sorties » du modèle sont entièrement déterminées par les « intrants » (figure 1.2.9). Un modèle déterministe reproduit toujours le même comportement d’un système si les paramètres et les conditions initiales du modèle demeurent identiques. Par exemple, le modèle logistique (équation 1) est déterministe. Pour des valeurs données du taux de croissance r, de la capacité de soutien K, et de la taille initiale de la population N(t = 0), la taille N(t) de la population à un temps futur, comme prédit par le modèle, sera toujours la même.
Contrairement à un modèle déterministe, un modèle stochastique peut produire des résultats différents même lorsque les conditions sont inchangées. Plusieurs « sorties » peuvent être générées par les mêmes « intrants » (figure 1.2.9). Un modèle stochastique représente souvent un système dans lequel des processus, des interactions ou des évènements sont aléatoires. Par exemple, un modèle de propagation d’une maladie infectieuse pourrait inclure la probabilité qu’un individu sain, en contact avec un individu infecté, devienne ou non infecté.

Figure 1.2.9 Modèles déterministe et stochastique. Un modèle déterministe produit une seule sortie pour un intrant donné. Un modèle stochastique produit plusieurs sorties possibles pour un intrant donné.
Continu ou discret
Un modèle peut être continu ou discret. On dit qu’un modèle est continu lorsque les variables qui représentent les composantes du système peuvent prendre toutes les valeurs sur un intervalle donné. Par exemple, un modèle continu peut représenter la densité d’une population, la concentration d’une substance toxique, la température d’un lac, etc. En effet, ces variables peuvent prendre toutes les valeurs (par ex. la température peut être 5 °C , 8,5 °C, 15,11 °C, etc.).
Un modèle discret, par ailleurs, utilise des variables qui peuvent prendre seulement certaines valeurs sur un intervalle donné. Par exemple, un modèle discret peut représenter les essences d’arbres qui poussent sur un territoire (sapin baumier, épinette noire, pruche) ou encore les types d’utilisation du sol (agricole, urbain, commerciale, etc.). Dans les modèles récursifs, le temps est une variable discrète qui prend seulement des valeurs positives entières : t = 1, 2, 3, …, n.
Élaboration du modèle conceptuel
Nous avons appris qu’il existe différents types de modèles. Un modèle peut être mathématique ou récursif, déterministe ou stochastique, continu ou discret, etc. Cependant tout modèle doit nécessairement est construit à partir d’un modèle conceptuel.
Représentation d’un système
Le modèle conceptuel est un schéma qui représente les composantes et les processus principaux d’un système selon un objectif de recherche précis. Bien que tous les systèmes soient différents, certains attributs sont communs à tous les systèmes. La figure 1.2.10 est une représentation générale d’un système et de ses attributs principaux.

Figure 1.2.10 Représentation générale d’un système et de ses attributs principaux.
Un système est composé d’entités qui sont généralement hétérogènes et qui entretiennent entre elles des interactions diverses. Ces entités peuvent faire partir du système de façon permanente ou temporaire. Certains systèmes sont modulaires : ils contiennent un ou plusieurs sous-systèmes composés d’entités fortement liées entre elles. Ces modules exhibent une certaine indépendance face aux autres entités du système.
Un système se définit par rapport à son environnement externe. Il possède une frontière qui l’en sépare. Un système peut être fermé ou ouvert. Un système fermé est entièrement isolé de l’environnement extérieur. Un système ouvert possède une frontière poreuse et il échange de l’énergie et de la matière avec l’environnement extérieur.
Considérations générales
Un modèle conceptuel est toujours développé en fonction d’objectifs de recherche précis. Ainsi, pour un même système, le choix des entités et des interactions à représenter peut différer selon les objectifs. Un principe important en modélisation est celui de la parcimonie. Il faut choisir judicieusement les entités et les interactions du système avec suffisamment de précision pour répondre aux objectifs de recherche sans toutefois créer un modèle inutilement compliqué. La facilité avec laquelle on peut interpréter la dynamique d’un modèle est souvent liée au niveau de précision et à la quantité d’informations intégrés dans son développement.
Ces considérations s’appliquent aussi à la définition de la frontière et des échanges avec l’environnement extérieur. Nous avons appris au module 1.1 que les systèmes environnementaux sont des systèmes ouverts pour lesquels il est parfois difficile de définir clairement les frontières. Pour certaines questions de recherche, il peut être utile de modéliser un système comme s’il était fermé, c’est-à-dire de modéliser seulement certains échanges avec l’environnement extérieur. Dans d’autres cas, il peut être utile de supposer que ces échanges soient constants dans le temps, même si la réalité est différente. Par exemple, un modèle de dynamique de la population d’un mammifère herbivore pourrait ne pas inclure la variation annuelle des précipitations qui, autrement, affecte la disponibilité de la ressource végétale dont l’herbivore se nourrit.
Le choix des entités, des interactions et des frontières dépend souvent de l’échelle temporelle et des échelles spatiales liées au système étudié. Reprenons l’exemple de la dynamique de population d’un mammifère herbivore. Un modèle développé avec l’objectif de comprendre comment la distribution hétérogène des ressources sur le territoire influence la croissance de la population au cours d’une saison pourrait inclure explicitement la dimension spatiale du territoire, la variabilité dans la croissance et dans la distribution des ressources, et des informations sur la capacité de déplacement de l’animal. Cependant, un modèle développé avec l’objectif d’étudier la dynamique à long terme de la population, par exemple sur plus de 100 ans, pourrait négliger d’inclure la dimension spatiale du territoire et inclure l’influence de l’augmentation annuelle de la température sur la disponibilité des ressources.
Le développement d’un modèle conceptuel nécessite donc des choix difficiles puisque ces choix auront une influence sur la dynamique produite par le modèle et sa concordance avec le système étudié.
Le modélisateur doit s’interroger sur les aspects suivants :
- Quelles sont les entités et les interactions du système à l’étude?
- Quel niveau de précision est approprié pour répondre aux objectifs de recherche?
- Le système est-il ouvert ou fermé?
- Quelles sont ses frontières?
- À quelle l’échelle spatiale le système est-il étudié?
- Sur quelle échelle temporelle?
Terminologie
Au cours du développement d’un modèle conceptuel, le modélisateur doit définir les constantes, les paramètres et les variables du modèle pour le système qu’il cherche à représenter. Il est important de savoir distinguer ces termes (Jorgensen et Fath, 2011).
Constante : une valeur du modèle qui ne change jamais pour le système étudié. Par exemple, la constante gravitationnelle ou le point de congélation de l’eau sont des constantes.
Paramètre : une valeur du modèle qui est constante pour une situation donnée, mais qui peut varier dans d’autres situations. Dans le modèle logistique vu plus haut, K, la capacité de soutien, et r, le taux de croissance intrinsèque, sont des paramètres. Lorsque le modèle logistique est utilisé pour représenter la croissance du protozoaire Paramecium bursaria (voir la figure 1.2.7), les valeurs de K et r sont constantes (230 et 0,47 respectivement). Cependant, ces paramètres prennent d’autres valeurs lorsque le modèle est utilisé pour représenter la croissance d’un autre protozoaire.
Variable : une valeur du modèle qui change en fonction du temps. Il y a deux types de variables : les variables d’état et les variables de forçage.
Variable de forçage : une variable de forçage représente une entité de l’environnement externe qui influence le système modélisé. Par exemple, dans une modèle d’eutrophisation d’un lac, la quantité de nutriments déversés dans l’eau sous forme de rejets agricoles, est une variable de forçage. Les variables de forçage sont souvent décrites par des fonctions mathématiques qui indiquent comment elles varient dans le temps. La température, la salinité de l’eau, la disponibilité de la lumière, le vent, ou les précipitations, sont d’autres exemples d’intrant dont les fluctuations temporelles affectent l’état d’un écosystème et qui peuvent être modélisées sous forme de variables de forçage.
Variable d’état : une variable d’état est une variable qui représente une entité du système modélisé. Par exemple, une variable d’état dans un modèle d’eutrophication d’un lac serait la concentration de phosphore dans le lac. Une variable d’état dans un modèle du bilan de carbone d’une forêt serait la quantité de carbone séquestrée par la biomasse aérienne. De même, une variable d’état dans un modèle de la dynamique d’une espèce végétale ou animale serait l’abondance de cette espèce. Par exemple, dans le modèle logistique N(t) est une variable d’état (équations 1 et 2).
De plus, l’état d’un système modélisé correspond à la valeur de chacune de ses variables d’état à un temps donné (figure 1.2.11).
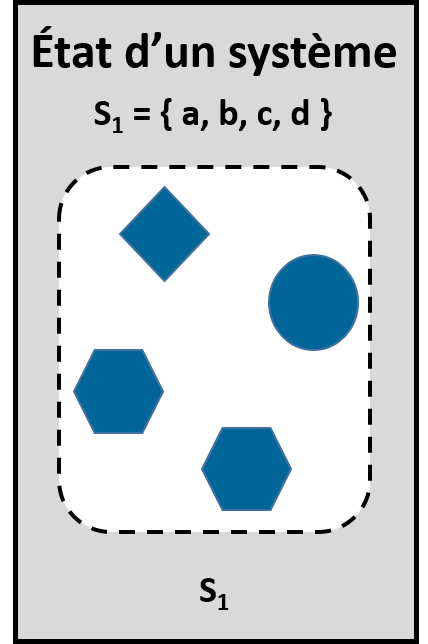
Figure 1.2.11 État d’un système au temps t = 1 composé de quatre entités dans S1 = (a, b, c, d).
La dynamique d’un système correspond à l’évolution temporelle de l’état d’un système (figure 1.2.12).
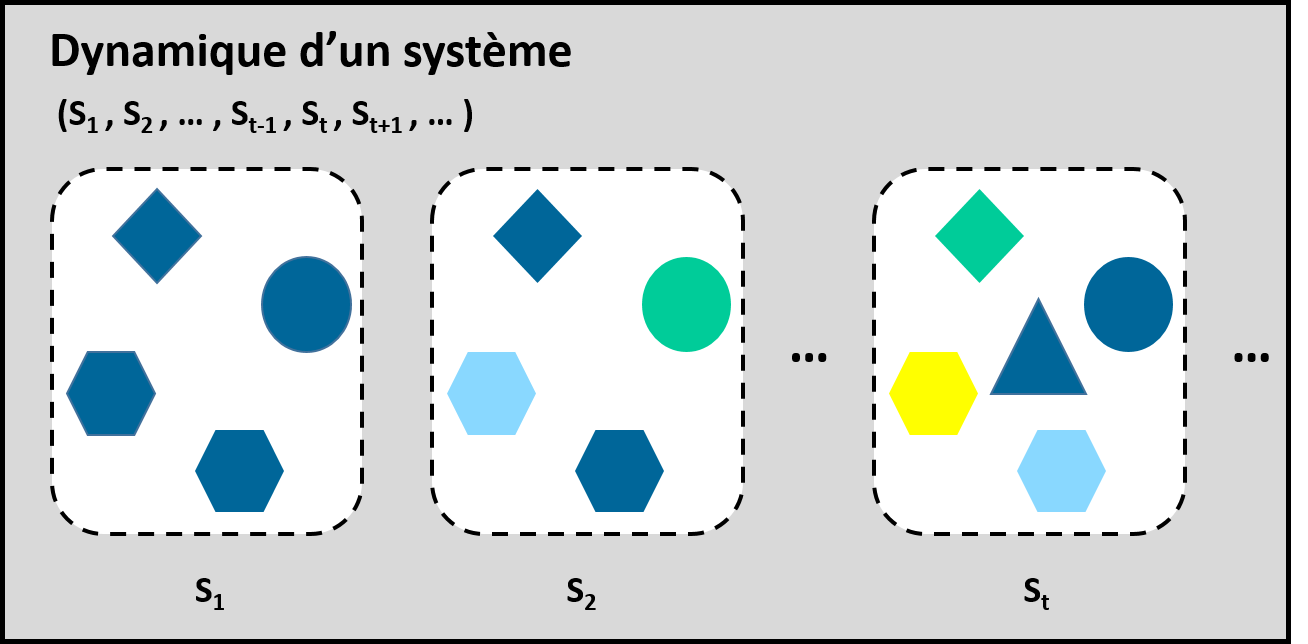
Figure 1.2.12 Dynamique d’un système dont l’état change en fonction du temps S1, S2, …, St-1, St, St+1, …
Le processus de modélisation
La modélisation d’un système doit passer par un processus rigoureux qui comprend plusieurs étapes depuis l’observation empirique du système étudié jusqu’à l’analyse des résultats produits par le modèle final.
Dès 1979 la Society for Computer Simulation (SCS) proposait un processus de modélisation afin de normaliser les étapes de la conception d’un modèle de simulations (Schlesinger et al. 1979). Le processus de modélisation procure une marche à suivre aux modélisateurs et assure la crédibilité des modèles développés. Nous allons maintenant lire le court rapport rédigé par le comité technique de la SCS sur la crédibilité des modèles, qui explique les étapes du processus de modélisation.
La figure 1.2.13 représente le processus de modélisation par un schéma analogue à celui décrit par Schlesinger et al.

Figure 1.2.13 Le processus de modélisation. Figure adaptée de Schlesinger et al. (1979) et Parrott (2003).
Au cours du processus de modélisation trois modèles sont élaborés : le modèle conceptuel, le modèle descriptif et le modèle informatique.
Comme nous l’avons expliqué précédemment, le modèle conceptuel est une représentation simplifiée du système réel. Par une analyse du système réel, le modélisateur dégage les composantes et les processus importants pour un domaine d’application particulier.
Le modèle descriptif est une formulation du modèle conceptuel par une description symbolique. Les processus et leurs effets sur les composantes du système sont exprimés par des règles de transition ou des fonctions mathématiques qui relient entre elles les variables, les paramètres et les constantes du modèle.
Le modèle informatique est construit par une implémentation informatique du modèle descriptif. Le modélisateur utilise un langage de programmation informatique (par exemple C, Java, Fortran, R ou MATLAB) pour traduire les relations symboliques exprimées dans le modèle descriptif. Le modélisateur conçoit ainsi un programme informatique qui sera exécuté par un ordinateur. Vous pouvez consulter les pages wikipédia sur les programmes informatiques et le langage de programmation si vous désirez en apprendre davantage sur le sujet. La simulation du modèle informatique permet d’explorer le comportement du modèle.
Le processus de modélisation compte plusieurs étapes de contrôle qui visent à s’assurer de la crédibilité du modèle élaboré. Ces étapes sont la qualification, la vérification et la validation.
L’étape de la qualification examine si le niveau d’abstraction utilisé pour concevoir le modèle conceptuel est adéquat pour représenter le système étudié dans les limites du domaine d’application visé. Par exemple, le modèle logistique (équation 1) peut être adéquat pour représenter la croissance d’une espèce de protozoaires lorsqu’elle est cultivée seule en laboratoire (voir la figure 1.2.7). Cependant, ce même modèle peut être inadéquat lorsque cette espèce est cultivée avec une autre espèce avec laquelle elle est en compétition pour l’utilisation de ressources limitées. Les limites du domaine d’application sont généralement déterminées par un ensemble de conditions sur le modèle. Au cours de la qualification, le modélisateur devra s’interroger sur son choix des processus, des composantes principales, des frontières et des échelles spatiales et temporelle du système à représenter (voir la sous-section Considérations générales plus haut).
L’étape de la vérification consiste à évaluer la cohérence interne du modèle informatique. C’est une étape technique qui détermine la fidélité et l’exactitude avec laquelle le modèle conceptuel est traduit en code informatique ou par des équations mathématiques (Law et Kelton, 1991, Aral, 2010). Est-ce que le comportement du modèle informatique concorde avec le comportement souhaité par le modélisateur? Le modélisateur vérifie si l’approche de modélisation choisie est convenable, il élimine aussi les erreurs de programmation (Coquillard et Hill, 1997).
L’étape de la validation consiste à comparer le comportement du modèle avec celui du système réel. Le modélisateur détermine si le modèle reproduit de manière satisfaisante le système réel étudié. La validité d’un modèle est établie pour un domaine d’application visé. Par exemple, un modèle de croissance forestière pourrait être valable en forêt tropicale mais pas en forêt boréale. En dehors de ce domaine d’applicabilité, il est possible que le modèle ne soit pas valable. De plus, la validité du modèle est souvent restreinte à une plage de valeurs de ses paramètres et de ses variables. Ceci signifie que le modèle peut être valable pour certaines valeurs de ses paramètres mais pas pour d’autres. Par exemple, un modèle reproduisant la dynamique des feux de forêt pourrait être valable pour les conditions climatiques antérieures mais s’avérer inexacte dans un contexte de changement climatique où des facteurs additionnels doivent être considérés comme l’influence du climat sur le régime de précipitations et sur l’occurrence d’autres perturbations naturelles (épidémies d’insectes, tempêtes de verglas, vents violents) qui affectent le risque, la fréquence, l’intensité et la durée des feux (Dale et al., 2001).
Au cours du processus de modélisation, le modélisateur doit paramétrer et calibrer le modèle. Le paramétrage consiste à fournir des valeurs aux paramètres du modèle. Généralement ces valeurs sont dérivées à partir de mesures prises en laboratoire ou sur le terrain, ou encore dans la littérature scientifique. Cependant, il est fréquent que la valeur d’un paramètre soit inconnue ou connue de façon approximative seulement. Ainsi, un ensemble de valeurs devra être testé et seules la ou les valeurs pour lesquelles le comportement du modèle est réaliste seront conservées. La calibration consiste justement à examiner le comportement du modèle et à ajuster la valeur donnée aux paramètres afin que celui-ci reproduise le comportement souhaité. Lorsqu’un modèle informatique ne peut être calibré, les modèles conceptuel et descriptif devront possiblement être réévalués. Le paramétrage et la calibration précèdent l’étape de la vérification. La vérification du modèle s’effectue généralement en comparant le comportement du modèle à un ensemble d’observations réelles autres que celles aillant servie à faire le paramétrage (Aral 2010).
L’analyse de sensibilité fait aussi partie du processus de modélisation. Elle consiste à évaluer les changements dans le comportement du modèle en fonction du changement des valeurs attribuées aux paramètres ou du changement des fonctions mathématiques utilisées pour représenter les processus et les interactions du système étudié.
L’analyse de sensibilité s’effectue pendant ou après l’étape de la validation. Elle comporte plusieurs objectifs (Aral, 2010). D’abord, elle sert à délimiter le domaine d’applicabilité du modèle : pour quelle plage de valeurs des paramètres le comportement du modèle est-il en accord avec le système réel? De plus, elle permet de déterminer les paramètres pour lesquels un changement de valeurs influence fortement la réponse du modèle. Ces paramètres pourraient faire l’objet de recherche supplémentaire afin de connaître leur valeur avec une meilleure précision. Finalement, l’analyse de sensibilité permet d’étudier le comportement du système modélisé aux valeurs de paramètre pour lesquels sa réponse est sensible. Par exemple, l’eutrophisation d’un lac peu profond peut survenir soudainement sous l’accumulation graduelle de nutriments tels le phosphore (Scheffer et al., 2001). Un modèle d’eutrophisation pourrait chercher à comprendre comment ce changement d’état survient en explorant le comportement du modèle pour des quantités de phosphore proches du seuil de transition.
Il est important de préciser que le processus de modélisation est un exercice itératif. Le modélisateur ne procède pas à la qualification, la vérification et la validation de façon linéaire – ceci est illustré par les flèches rouges bidirectionnelles marquant les différentes étapes du processus. Au cours de ces étapes le modélisateur est amené à revoir les modèles conceptuel, descriptif et informatique. Ces modèles seront alors ajustés, précisés, ou corrigés et devront être soumis à nouveau aux étapes de qualification, vérification et validation.
En conclusion, rappelons qu’un modèle est une simplification de la réalité. La validité d’un modèle et son applicabilité sont dépendantes de ces simplifications. Sur ce sujet cette citation du statisticien George Box est particulièrement éloquente: « Remember that all models are wrong; the practical question is how wrong do they have to be to not be useful » (Box et Draper, 1987). Lors de l’utilisation d’un modèle ou des résultats produits par ce modèle, il est impératif de communiquer clairement les simplifications qui ont été employées pour sa construction.
Pour compléter le module 1.2, vous allez maintenant réaliser une activité d’autoévaluation. Cette activité vous permet d’évaluer votre compréhension des concepts théoriques vus dans les modules 1.1 et 1.2. Vous serez à même de juger de votre capacité à définir les objectifs de la modélisation en environnement, à employer la terminologie technique en modélisation, à décrire les caractéristiques principales d’un modèle, et à décrire le processus de modélisation. Une maîtrise de ces concepts est importante pour comprendre les approches de modélisation qui seront présentées dans la partie 2 du cours et pour apprécier le processus de modélisation qui sous-tend les modèles de gestion des ressources environnementales qui seront présentés dans la partie 3.
Références
Aral, M. M. (2010). Principles of environmental modeling. Dans M. M. Aral (dir.), Environmental modeling and healthh risk analysis (p. 37-61). Dordrecht: Springer.
Coquillard, P. et Hill, D. R. C. (1997). Modélisation et Simulation d’Ecosystèmes : des modèles déterministes aux simulations à événements discrets. Paris: Masson.
Dale, V. H., Joyce, L. A., McNulty, S., Neilson, R. P., Ayres, M. P., Flannigan, M. D., . . . Michael Wotton, B. (2001). Climate Change and Forest Disturbances. BioScience, 51(9), 723-734. doi: 10.1641/0006-3568(2001)051[0723:CCAFD]2.0.CO;2
Engelen, G., White, R., Uljee, I. et Drazan, P. (1995). Using cellular automata for integrated modelling of socio-environmental systems. Environmental Monitoring and Assessment, 34(2), 203-214. doi: 10.1007/BF00546036
JeLuF. (2003). Canal aérodynamique. Repéré à https://commons.wikimedia.org/wiki/File:Windkanal.jpg , licence: https://creativecommons.org/licenses/by-sa/3.0/deed.en
Johndedios. (2011). Biosphere 2. Repéré à https://commons.wikimedia.org/wiki/File:Wiki_bio2_sunset_001.jpg, licence: https://creativecommons.org/licenses/by/3.0/deed.en
Jordiferrer. (2007). Shanghai urban planning exhbition center. Repéré à https://commons.wikimedia.org/wiki/File:Shanghai_2020_-_Urban_Planning_Exhibition_Center_-_01.JPG , licence: https://creativecommons.org/licenses/by-sa/3.0/deed.en
Jørgensen, S. E. et Fath, B. D. (2011). Spatial modelling (Fundamentals of ecological modelling (p. 347-368). Oxford: Elsevier.
Law, A. M. et Kelton, D. W. (1991). Simulation modeling and analysis. New York: McGraw-Hill.
Quinton, J. N. (2004). Erosion and sediment transport. Dans J. Wainwright et M. Mulligan (dir.), Environmental Modelling: Finding simplicity in complexity (p. 187-197). West Sussex: Wiley-Blackwell.
Roughgarden, J. (1979). Theory of population genetics and evolutionary ecology: An introduction. New York: Macmillan Publishing Company.
Scheffer, M., Carpenter, S., Foley, J. A., Folke, C. et Walker, B. (2001). Catastrophic shifts in ecosystems. Nature, 413(6856), 591-596.
Schlesinger, S., Crosbie, R. E., Gagne, R. E., Innis, G. S., Lalwani, C. S., Loch, J., . . . Bartos, D. (1979). Terminology for model credibility. Simulation, 32(3), 103-104.
Stinson, G., Kurz, W. A., Smyth, C. E., Neilson, E. T., Dymond, C. C., Metsaranta, J. M., . . . Blain, D. (2011). An inventory-based analysis of Canada’s managed forest carbon dynamics, 1990 to 2008. Global Change Biology, 17(6), 2227-2244. doi: 10.1111/j.1365-2486.2010.02369.x
Vandermeer, J. H. (1969). The competitive structure of communities: an experimental approach with protozoa. Ecology, 50(3), 362-371. doi: 10.2307/1933884
Williams, S. E., Williams, Y. M., VanDerWal, J., Isaac, J. L., Shoo, L. P. et Johnson, C. N. (2009). Ecological specialization and population size in a biodiversity hotspot: How rare species avoid extinction. Proceedings of the National Academy of Sciences, 106(Supplement 2), 19737-19741. doi: 10.1073/pnas.0901640106